





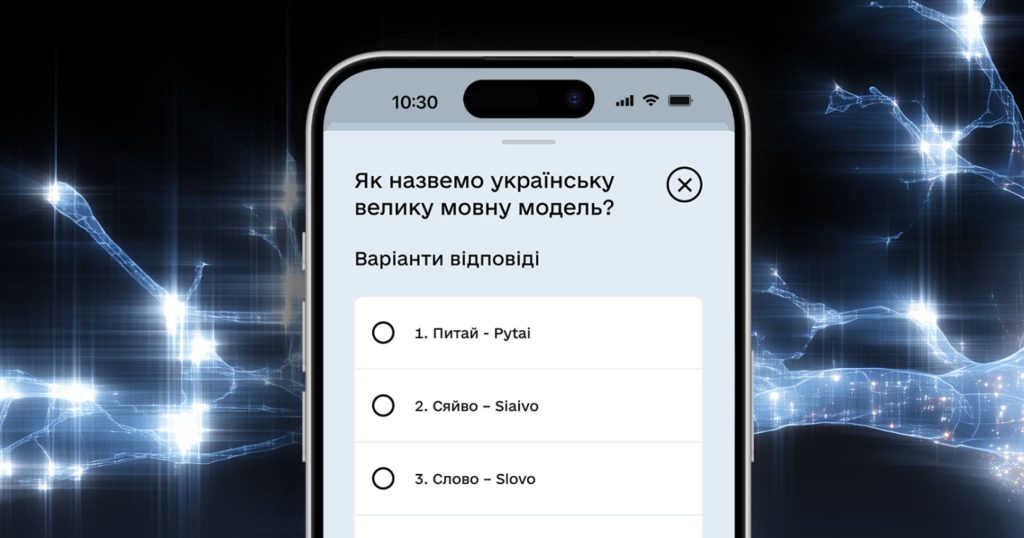
Мінцифри та «Київстар» працюють над створенням національної великої мовної моделі. Назву для неї можна обрати через голосування в «Дії». Про це для DOU розповіли в міністерстві.
Читайте также: Мстислав Банік став заступником міністра оборони — за що він відповідатиме
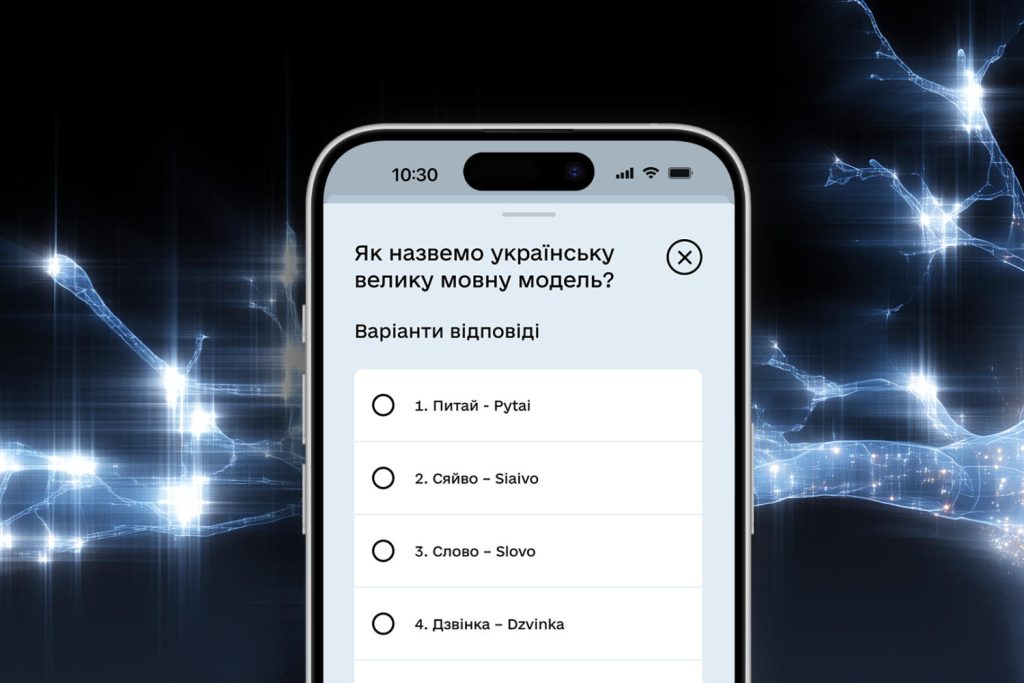
Користувачі подали понад три тисячі варіантів назв для LLM, із яких відібрали десять:
- Сяйво — Siaivo
- Питай — Pytai
- Слово — Slovo
- Дзвінка — Dzvinka
- Говерла — Hoverla
- Шипіт — Shypit
- Шукай — Shukаі
- Ядро — Yadro
- Кавун — Kavun
- Гомін — Homin
«Один з головних критеріїв — відповідність вимогам права інтелектуальної власності», — зазначили у відомстві.
Проголосувати можна в застосунку «Дія» у розділі «Сервіси» — «Опитування», обравши один із запропонованих варіантів. Голосування триватиме до 29 березня 12:00.
📌 Про національну LLM
У лютому 2025 року Мінцифри презентувало новий ШІ-підрозділ, який назвали AI Centre of Excellence. Однією з цілей проєкту було розробити національну мовну модель для державних сервісів.
Читайте также: «Це одна з найбільш проклятих посад у війську». Історія ІТ-фахівчині, яка командує ротою ударних БПЛА
Згодом до розробки LLM долучився Київстар. Упродовж 2025 року проєкт деталізували: сформували команду, визначили, що дані збиратимуть разом з університетами та іншими інституціями, а також заклали ідею, що модель стане базою для майбутніх продуктів на кшталт Дія.AI.
Наприкінці 2025 року з’явилась конкретика щодо технічної основи: як базову модель обрали Gemma від Google, яку адаптуватимуть під українську мову.
Також в інтерв’ю DOU та «УТ-2» т.в.о. міністра цифрової трансформації Олександр Борняков розповідав, що старт LLM затягнувся через труднощі зі збором даних та наймом айтівців.
Читайте также: В Україні мобільний інтернет зростає швидше за домашній. Як змінювалися місця в рейтингу Ookla
Все про українське ІТ в телеграмі — підписуйтеся на канал DOU



